Where in the previous blogs we went over OpenCV's techniques for facial detection particularly, using YOLO, we will now be able detect anything we would want to, provided we have the necessary dataset to train the model on. In this case, we will be utilizing a custom dataset containing all the necessary training, testing, and validation images in the proper format for YOLOv11.
If you want to make your own dataset, I would recommend utilizing the free features available to you on Roboflow. This video is a huge help for determining how to go through the annotation process. For sourcing images for your dataset, Kaggle is a great help! Make sure you cite your sources if using your dataset in a work you plan on publishing.
YOLO is used even more frequently than the previous techniques we reviewed. It has become the standard in real-time object detection, thanks to its incredible speed, which is continually increasing as it is improved year after year. Be it faces, or cars, or any thing else that a user may want to detect, YOLO presents the tools for doing such things, and doing them quickly and efficiently, provided the user can supply it with a properly structured dataset.
Compared to the amount of pre-processing and extra steps that were required when utilizing OpenCV, another advantage of YOLO becomes abundantly clear during implementation, namely how simple the entire pipeline is, from training to prediction. In the following code, we provide YOLO with out dataset, and it handles all the training. Because we are running 50 training epochs, it will run for roughly 9-12 minutes thanks to the GPU we are utilizing for this runtime. After that point, we will be able to move on.
# Load a model
model = YOLO("yolo11s.pt") # load a pretrained model (recommended for training)
# Train the model
training = model.train(data="/content/fish_dataset.v4-fish-v4.yolov11/data.yaml", epochs=50, imgsz=640)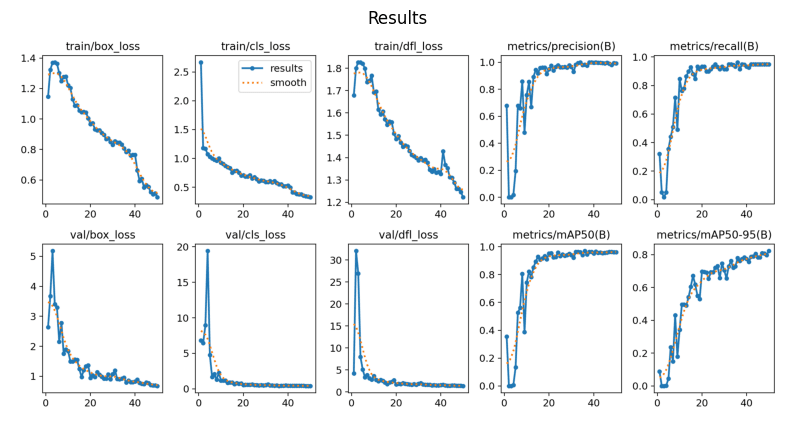
After running the training process, a number of different things are saved, presenting us with how the training process went. The most important of these is stored within the results.png image. Provided the training is going according to plan, what we should observe is an inverse relationship between the different types of loss and minimum average precision and recall.
My result is saved after training, but ensure you run this code after doing the training process to review your own results before continuing. Additionally, the path to the results image may change after training on your end, so verify in the previous code block where your results are saved to.
image = plt.imread("/content/runs/detect/train2/results.png")
# Display the results image
create_mpl_figure(10,10, [image], ["Results"])Now that the model has been trained, and the results of its training have been observed to be reliable, we can now going about actually testing its ability to detect the class on which it was trained, which is in this case, fish.
In similar fashion to the displaying of the results image, ensure that the path to the image is correct after running the prediction. You may need to change the path for the pred_test variable according to wherever the results are saved.
# Run the model against a test image, verifying that it properly identifies the custom class
prediction = model("/content/fish_dataset.v4-fish-v4.yolov11/test/images/P1ROZC-Z_7_jpg.rf.745f9956e192bf19ef2ebd8a7ede9d26.jpg", save=True)pred_test = plt.imread("/content/runs/detect/train23/P1ROZC-Z_7_jpg.rf.745f9956e192bf19ef2ebd8a7ede9d26.jpg")
# Display the test image after it is fed through the Model
create_mpl_figure(5,5, [pred_test], ["Prediction Test"])
And just like that, you are able to detect custom objects using the YOLO algorithm! Not only is it exceedingly fast, but it is very easy to implement and train custom models on!


