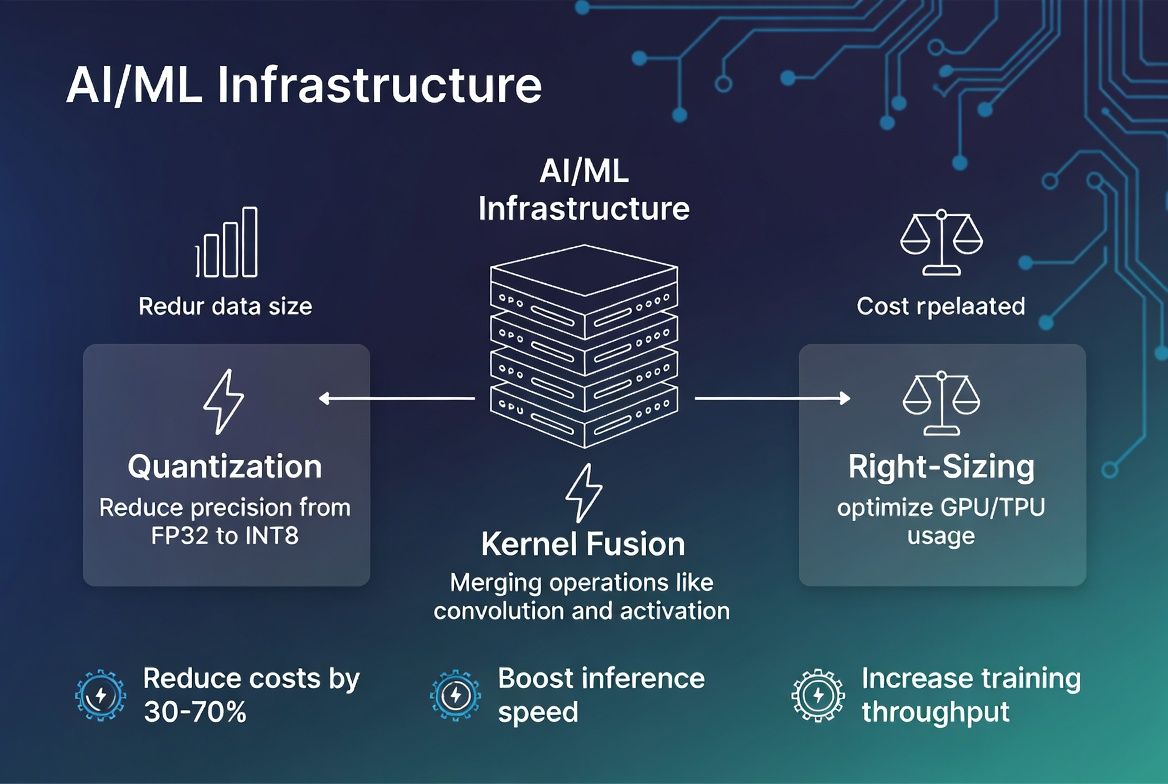
Slash your AI/ML infrastructure costs by 30–70% while boosting inference speed and training throughput with our expert GPU optimization—covering quantization, kernel fusion, right-sizing, and continuous monitoring across A100, H100, L40S, and other GPU families.
Identify inefficiencies across your entire GPU stack—cloud instances, on-prem hardware, containers, models, and pipelines. We pinpoint bottlenecks in compute, memory, networking, and execution.


Dramatically reduce model size and inference latency with advanced quantization techniques—INT8, INT4, mixed-precision—while maintaining accuracy. Faster serving, lower memory, smaller bills.
Slash inference time and training cycles with kernel fusion, compiler optimizations, and efficient serving frameworks. Deploy vLLM, TensorRT, and custom kernels for maximum throughput.


Match GPU hardware to workload requirements. We analyze A100, H100, L40S, RTX, MI300, and other architectures to recommend optimal instance families—balancing performance and cost.
Streamline ML pipelines and containerized workloads for GPU efficiency. We optimize Docker images, Kubernetes scheduling, batch processing, and caching to maximize GPU utilization.

Sustain 30–70% cost savings as workloads evolve. We provide real-time GPU metrics, performance dashboards, and proactive optimization recommendations to maintain peak efficiency.