Imagine having a virtual assistant that understands user preferences, context, and queries with precision—providing relevant and tailored responses in seconds. This is the promise of an AI-powered chatbot, a tool designed to make interactions more intuitive, efficient, and personalized using OpenAI API and Retrieval-Augmented Generation (RAG) frameworks such as LangChain.
Problem
The internet is flooded with information, forums, and resources, making it difficult to find precise and relevant answers. While this abundance is useful, it also presents challenges:
These challenges highlight the need for a smarter, more efficient solution—one that leverages AI to deliver personalized, context-aware interactions in real-time. In the next sections, we'll explore how combining the OpenAI API with LangChain can address these issues and revolutionize AI-driven communication.
Architecture Overview
1. Key Components
The chatbot consists of the following core components:
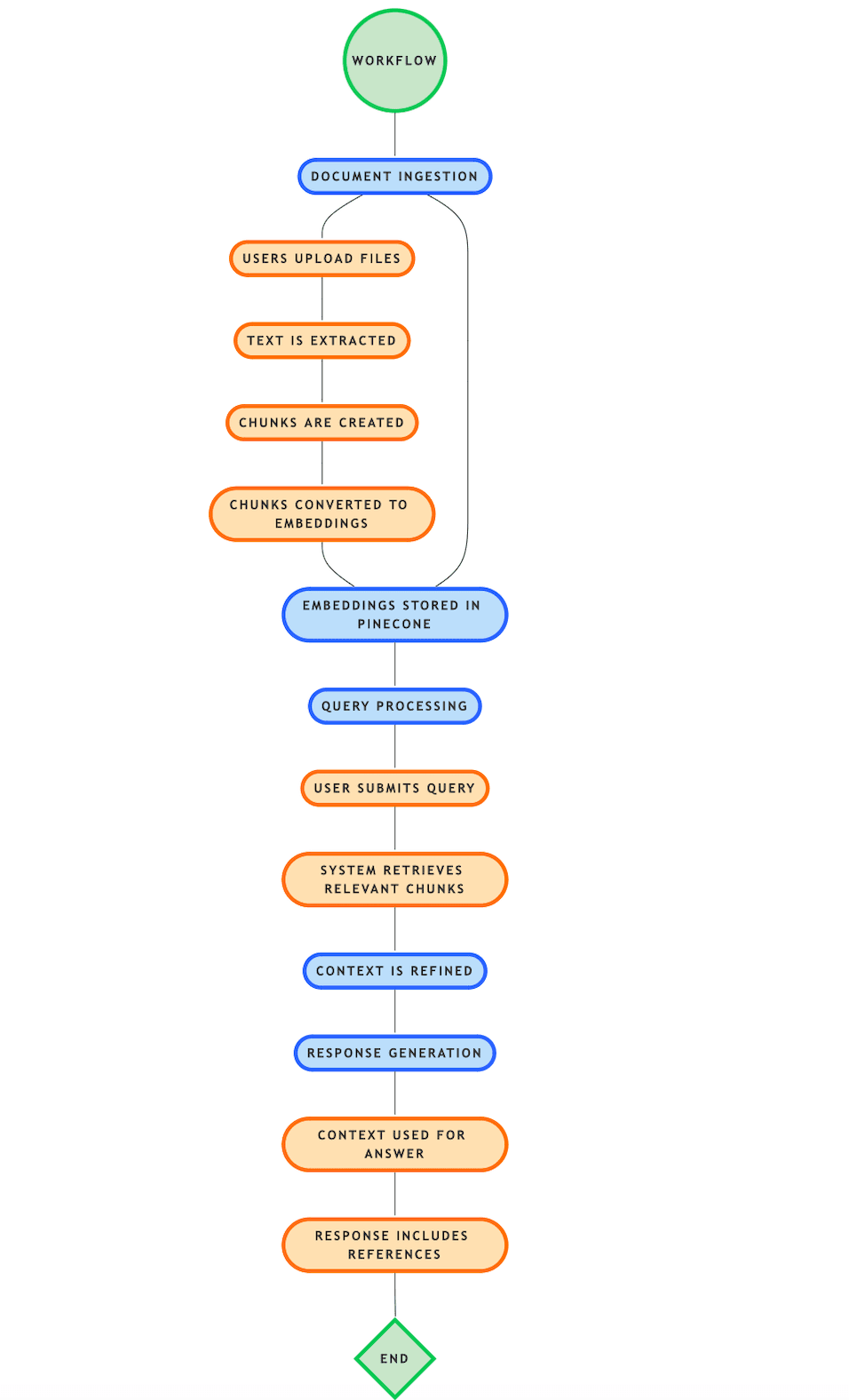
2. Workflow
Setting Up the Environment with Docker
Step 1: Creating the Dockerfile
Create a Dockerfile for the FastAPI backend:
# Use an official Python runtime as the base image
FROM python:3.9-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file into the container
COPY requirements.txt ./
# Install the dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the application code into the container
COPY . ./
# Expose the port the app runs on
EXPOSE 8000
# Define the command to run the application
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]Step 2: Setting Up Docker Compose
Create a docker-compose.yml file to manage the backend and frontend services:
services:
backend:
build:
context: .
dockerfile: Dockerfile
container_name: chatbot-backend
volumes:
- .:/app
env_file:
- .env
ports:
- "8000:8000"
command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
frontend:
build:
context: ./chatbot-ui
dockerfile: Dockerfile
container_name: chatbot-frontend
volumes:
- ./chatbot-ui:/app
- /app/node_modules
ports:
- "3000:3000"
command: npm startStep 3: Running the Containers
docker-compose up --builddocker-compose up --buildRetrieval and Generation Pipeline
In this document, we will walk through the steps to build a Retrieval and Generation (RAG) pipeline, a key component of many advanced AI systems. This pipeline combines retrieval from a knowledge base (vector database) with generative AI to produce accurate and contextually relevant answers to user queries. Here you can find the repository with a sample of the project we are about to build: Sample AI Chatbot.
Step 1: Set Up the Knowledge Base
The knowledge base is the foundation of the RAG pipeline. It stores relevant information in a vectorized format for efficient retrieval.
index.upsert([ {"id": "1", "vector": embedding, "metadata": {"text": chunk_text}} ])Step 2: Build the Retrieval Component
The retrieval component searches the vector database for the most relevant chunks based on a user query.
results = index.query( vector=query_embedding, top_k=5, include_metadata=True ) Step 3: Connect with a Generative Model
Use a generative model like OpenAI’s GPT to create a final answer by combining the retrieved context and user query.
Context: <retrieved_context> Question: <user_query> Answer: response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "system", "content": prompt}] )Steps to Build the Indexing Pipeline
Step 1: Extracting Text from Documents
from PyPDF2 import PdfReader
def extract_text_from_pdf(content: bytes, filename: str) -> list:
reader = PdfReader(io.BytesIO(content))
return [
{"text": page.extract_text(), "page_number": i + 1, "file_name": filename}
for i, page in enumerate(reader.pages) if page.extract_text().strip()
]Step 2: Splitting Text into Chunks
from langchain.text_splitter import CharacterTextSplitter
def split_document_with_metadata(chunks, chunk_size=1000, overlap=200):
splitter = CharacterTextSplitter(separator="\n", chunk_size=chunk_size, chunk_overlap=overlap)
return [
{"text": split, "page_number": chunk["page_number"], "file_name": chunk["file_name"]}
for chunk in chunks for split in splitter.split_text(chunk["text"])
]Step 3: Generating Embeddings
import openai
def generate_embeddings(text):
response = openai.OpenAI(api_key=OPENAI_API_KEY).embeddings.create(
input=text, model="text-embedding-ada-002"
)
return response.data[0].embeddingStep 4: Storing Data in Pinecone
from pinecone import Pinecone
import uuid
pc = Pinecone(api_key=PINECONE_API_KEY)
index = pc.Index("knowledge-base")
def insert_data_to_pinecone(chunks):
for chunk in chunks:
unique_id = str(uuid.uuid4())
embedding = generate_embeddings(chunk["text"])
index.insert([(unique_id, embedding, chunk)])Step 5: Retrieving Context from Pinecone
def search_vector_database(query, top_k=3):
query_embedding = generate_embeddings(query)
results = index.query(vector=query_embedding, top_k=top_k, include_metadata=True)
return [match["metadata"] for match in results["matches"] if match["score"] >= 0.85]Conclusion
In conclusion, building an AI-powered chatbot like our Recipe Assistant demonstrates how AI can transform information retrieval and enhance user interactions. By leveraging OpenAI API, LangChain, and vector databases like Pinecone, we addressed common challenges such as information overload and lack of personalization. Our architecture, built with FastAPI and Docker, provides a scalable and efficient foundation for AI-driven applications.
While our example focused on a recipe assistant, the same principles can be applied to various domains—from customer support and education to research assistants and beyond. Whether you're building a chatbot for a different use case or enhancing an existing system, the tools and methodologies discussed here offer a flexible starting point. The possibilities are endless—it's up to you to tailor this approach to your unique needs!